Scalable Server-Side Processing of Audio Files
![]() Damian Moore, Published: 5 May 2022
Damian Moore, Published: 5 May 2022
I’m happy to announce another big development to our server-side application architecture. It follows on neatly from our last article on the migration to object storage which was a prerequisite for this work.
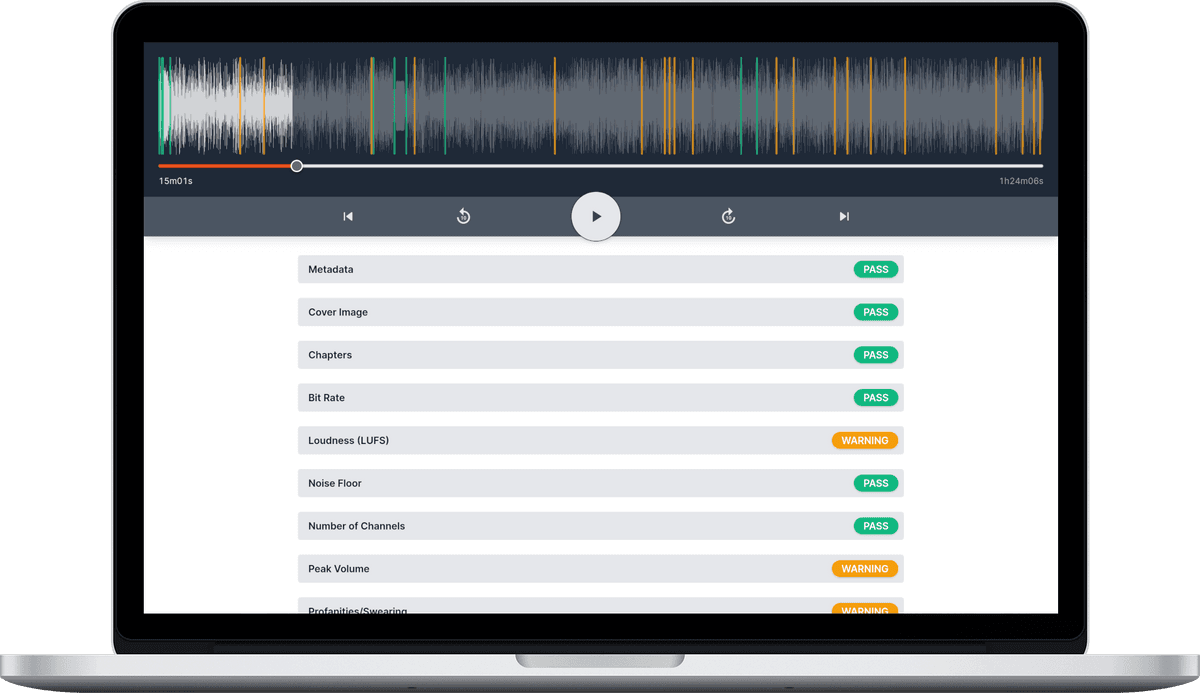
Analysing our customer’s audio files is quite intensive, requiring quite a lot of CPU and RAM resources to generate a report within a reasonable period of time.
With our current number of users, uploads are quite irregular so if we were to keep large machines running they would be idling for the vast majority of the time. As we grow, it’s also possible that multiple users will upload while someone else’s report is still processing — in this case we don’t want the subsequent user’s reports to be delayed.
With our new architecture, more worker machines get added when more work needs doing and then they are terminated (switched off) when not in use. We use Kubernetes as our container orchestrator running on Google Cloud using their Autopilot feature. Traditionally you would have to fix the size of your Kubernetes cluster upfront but Autopilot gives us the flexibility and simplicity we need as it deals with adding more node machines to the cluster as we increase the number of pod replicas in our specification.

The direct benefits are:
- Audio Audit’s costs are reduced by not paying for resources that aren’t in use, allowing us to provide the service at a reasonable price and develop the service further.
- More customers can be served their reports in a reasonable time as the service gains more popularity.
- It’s better for the environment as servers are re-allocated to other cloud customers when we’re not using them.
- Kubernetes provides rolling updates meaning there is no downtime when we release most new code and monitoring ensures there is always a healthy number of machines making us more reliable.
- Report generation reliability is improved as we had to adapt our job queuing to make sure it was resilient against processes and containers being killed abruptly.
There are, however, some downsides:
- There can be a delay of over a minute for new worker machines to be created — especially if Google has to provision new nodes in the cluster. We’ve counteracted this by using much higher-spec’d machines for the actual processing so they still finish faster. We should be able to optimise this startup time further by reducing the filesystem image size of our workers meaning they download faster.
- If there is a problem or we get lots of users, our bills could skyrocket! This could happen but we reduce the risk by setting quotas on the maximum CPU resources and monitoring customer usage.
Our initial benchmarking of the new system (from a 0 workers start) is showing that reports are generated in about 6% of the audio file length. For example an hour long podcast show would take less than 4 minutes from upload to report. We can tweak the resources for speed and efficiency as we gain more insights.
I hope this dive into our technical architecture was somewhat interesting to you. I think we have a strong foundation now to cope with all the processing we will hopefully have to deal with in the future.