New Feature: Unwanted Noise Detection
![]() Damian Moore, Published: 26 July 2024
Damian Moore, Published: 26 July 2024
I have an exciting new feature to announce today. It’s something that has been in development over the past few weeks and I think it’s something that will save the day for many podcasters. Firstly a bit of backstory…
Podcasts bring me news, entertainment and education in a medium that is personal and adds value to otherwise unproductive time. My podcast player (AntennaPod) shows that I listen to over 10 hours of podcasts each week. Each time I come across something in an episode that I think the producer would not have wanted, I make a note of it. Over the years this has become quite a long list and I regularly review it to see which ones could be made into new next checks.
One feature that has been on my wish list for a long time has been the ability to detect unwanted noises. It can be quite jarring (and unprofessional) when someone on a podcast coughs loudly, a dog barks or the host receives a non-silent notification on their phone.
After recently researching the feasibility of adding such a feature, I found a lot of good research on the topic. Thankfully it turned out that the main pieces of the puzzle were published and open source but it took a different kind of architecture and hardware to run it in a reasonable amount of time.
Technical Details
The model we use is called an “Audio Spectrogram Transformer (AST)” and comes from a paper written in 2021 by Yuan Gong, Yu-An Chung and James Glass.
Audio samples for training and evaluating the model first go through a “Transformer” which converts it to a spectrogram image of the frequencies. The model itself is purely attention-based with no convolution/CNN involved, making it more efficient.

The data for training this model comes from Google’s AudioSet dataset. It contains over 2 million human-labelled, 10 second clips of audio from YouTube. The samples are categorised into 527 labels. We use this dataset as our starting point and then filter it down to just sounds that we consider “unwanted”. If we didn’t do this then the check would be highlighting intended sounds like “Speech”, “Music” and “Laughing”.
We expect the main categories of unwanted noise in podcasts to be:
- Coughing
- Sneezing
- Phones (notifications, alarms, vibrations)
- Banging (knocking the desk or microphone)
- Pets (dogs barking, cats meowing, etc.)
- Cutlery, cups and other kitchen noises
- Traffic (horns, large vehicles, etc.)
- Doorbells, buzzers
Once the model was running it was clear that the quality was more than adequate. The problem was that it was slow to run — on my development laptop (a 7-year-old, Intel i7, 16GB RAM) using CPU only, it took about 1 second per second of audio. Therefore an hour-long podcast would take an hour to classify noises which was far too long. This was pretty disappointing after all the experimenting. I had already quantised the model weights and optimised the dataset loading by this point. The approach to running the model needed to be radically different if it was to go into production.
GPUs are much faster at running certain types of ML model. The libraries in use already had the ability to make use of Nvidia GPUs using Cuda so I wanted to experiment with a real GPU. I don’t have a physical GPU to connect to so I was looking at cloud-based solutions. The workload of Audio Audit is very “bursty” in that for the majority of the time there is not much processing going on and then when a new report is started, we want to complete it as quickly as possibly. Running a machine permanently in a datacenter with a GPU would be wasteful and much too expensive. Existing workloads like the speech-to-text transcription benefit from using a Kubernetes cluster that automatically adds large nodes to the pool when worker pods scale up.
Eventually I was able to find a serverless function provider that supports a range of Nvidia GPUs. The provider manages the machines, we upload a container to run a task and we only get charged for the number of seconds x RAM cost x GPU cost that it takes to run a task. We’re still evaluating the performance and cost but so far it looks suitable. If it proves itself over the next few weeks, we’ll probably migrate some of the other computationally expensive tasks onto the new serverless infrastructure.
Running an hour of audio through the model running on an A100 GPU takes just under 2 minutes which is very acceptable. We’ll continue to experiment with different GPUs as we get a better sense of the costs and how long the queue times are for each type.
How to Get Started
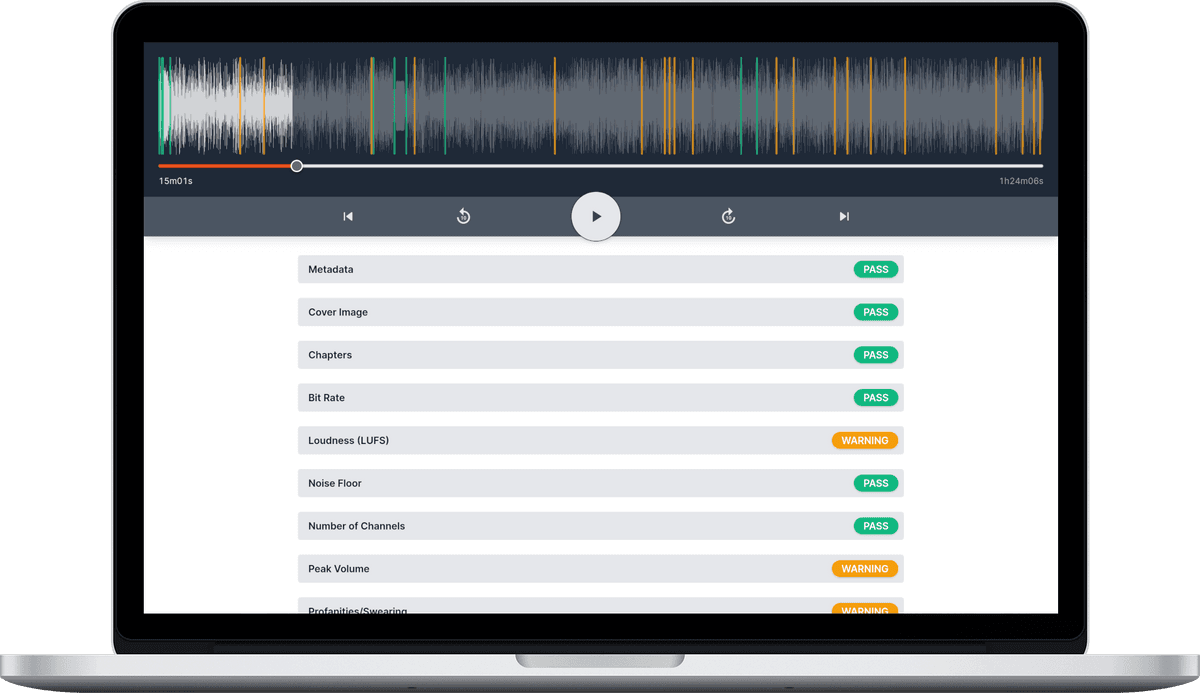
To begin using the feature, you don’t need to do anything in particular — just create a new report (or wait until your next episode get published if your feed is connected). When you view your report, you’ll see your score is now out of 17 checks.
If you scroll down to the “Unwanted Noises” check you’ll see an orange warning message if the AI has found something that is worth investigating. If you then click on the check you’ll see a list of the noises that were detected and at what time code. You can click on each of these detected noises and it will then start playing that point in time using the player at the top of the screen. You can also see the detected noises highlighted as orange bars on the player at the top (which are also clickable).

Conclusion
We hope you find the noise detection feature helps you to find undesirable sounds that can get missed in your audio files. It brings Audio Audit up to the next level in utilising the latest that AI can offer. It should save you time and increase the quality of your work.
I urge you to upload an MP3 or connect it to your feed to give it a try. We really want to hear your feedback and will use it to continue to improve this feature.
Keep an eye out in the coming months as we’ve got several other new features in the works. The best way to stay up-to-date is by following us on social media — LinkedIn, Twitter/X, Facebook or YouTube.
—
Photo courtesy of Towfiqu barbhuiya